

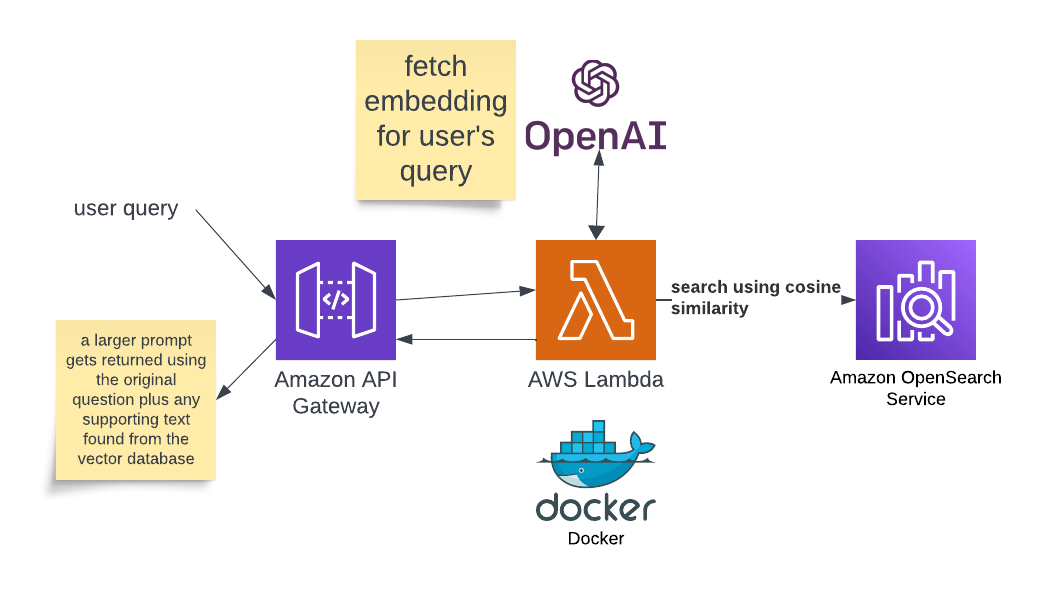
Architecture: Retrieval system
Walkthrough of our architecture decisions for searching text in a vector database.

Practical AI for Business
Practical AI for business use cases, brings home to something tangible
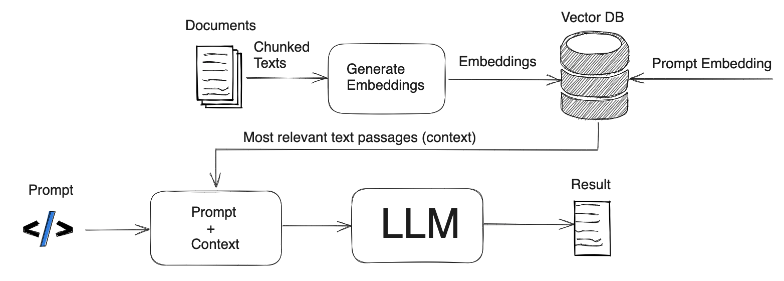
Planning Checklist for RAG projects (retrieval-augmented generation)
A list of business-centric things to figure out when building a Retrieval-Augmented Generation (RAG) system
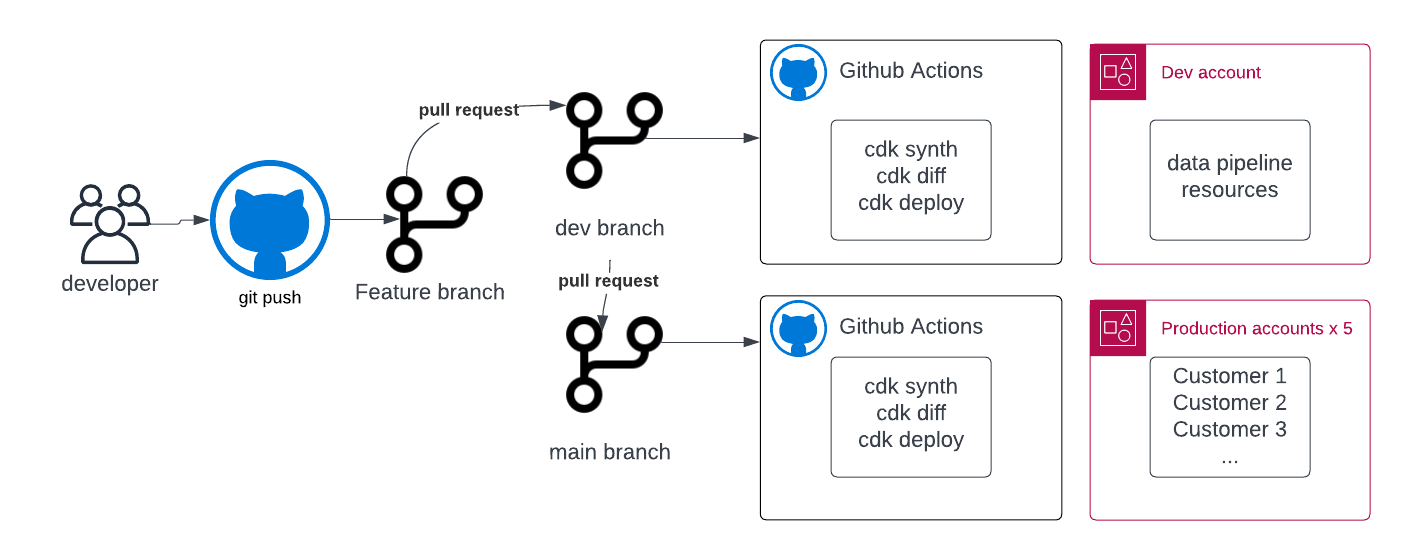
Multi-Account Deployment Using GitHub Actions and the AWS Cloud Development Kit (CDK)
Big Cloud Country employs practical, common-sense best practices for AWS multi-account deployment, combining Git flow, trunk-based development, and GitHub Actions with AWS CDK. Their disciplined development workflow emphasizes code quality and efficient deployment, featuring robust branch protection, reusable workflows, and matrix strategies. By utilizing GitHub Environments and an advanced CI/CD pipeline, they achieve secure, consistent, and streamlined deployments across various AWS accounts, showcasing a pragmatic approach to complex cloud deployment challenges.

Archiving Data in the Cloud: A Custom Solution for 100s of Terabytes of Raw Data
Big Cloud Country created a tailored tool to manage their huge and ever-growing AWS S3 data, which was challenging to handle with standard methods. They developed a custom Python script to selectively archive data, considering unique access patterns and interactions with other AWS services. This solution not only helped in significantly reducing storage costs but also ensured efficient and scalable data management, adapting to their specific needs.

Repartitioning in PySpark
How we made Glue jobs significantly faster by repartitioning data on its way in to the job.