
Planning Checklist for RAG projects (retrieval-augmented generation)
Retrieval-augmented generation (RAG) is a search technique where you give a large language model (LLM) a few chunks of text, and tell it to answer a question about those chunks of text. It’s a great alternative to fine-tuning a model, which can be expensive, time-consuming, and have uncertain benefits. With RAG, you take a query like “what does the tax code say about additions on my house?”, transform that into an embedding vector, compare that vector to all the vectors in your database of source text vectors, then take the top ~5 results and send it to the LLM to answer. So, in our example, the source text would be some city tax code, broken up into chunks and converted into embeddings. The top 5 results most closely related to the query about additions on the house get sent back from the database (retrieval). Then, with those 5 chunks as context, you generate a response (generation) from the LLM and send it back to the user.
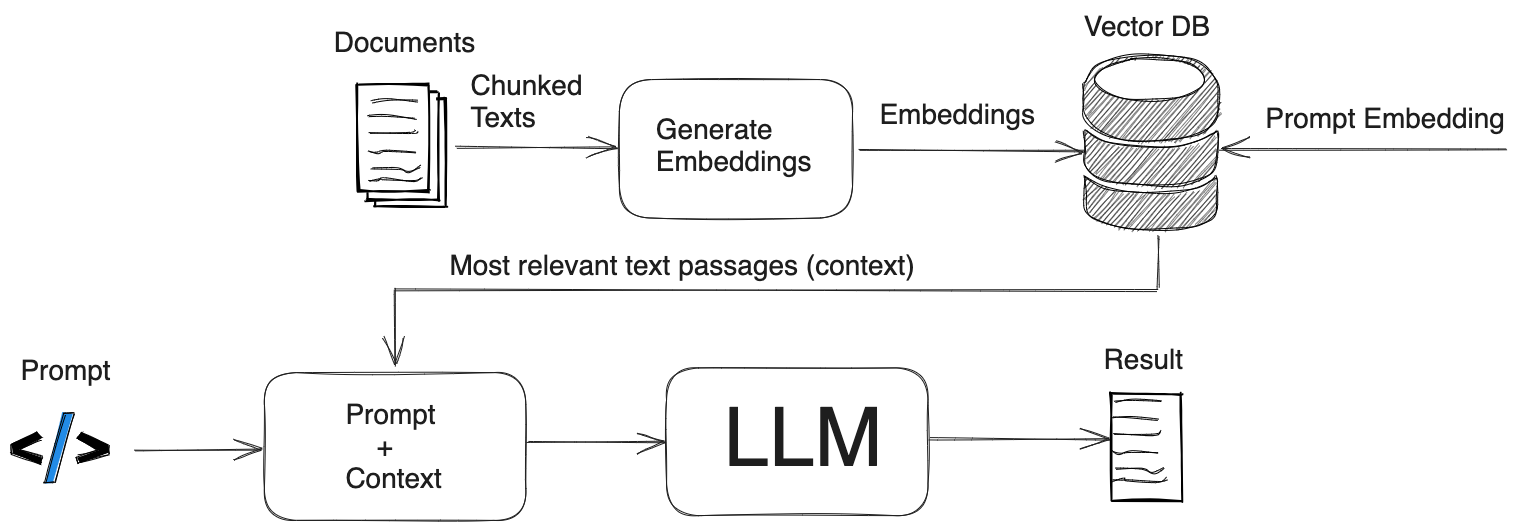
source: https://safjan.com/understanding-retrieval-augmented-generation-rag-empowering-llms/
Here’s a checklist of questions you’ll need to answer when planning out one of these projects.
Business impact and user experience
Who is the end user? What job are they trying to get done?
What is the business impact you're trying to get
Productivity -> reduced waste from inefficient searches
Efficiency -> route emails, mine structured data from PDFs instead of manually doing that
Training - help newcomers learn and share knowledge business-wide
What is the source(s) to be queried and what do you want the model to do in return?
What NLP tasks do you envision?
Question answering
Summarization
Text generation
Entity extraction
How will users use it -
Chat interface
API
inside an application
Data engineering and processing
How many documents? Size of text to be analyzed?
Where are the documents currently stored?
Figure out the pathway for ingesting the documents into S3
Is your PDF table-heavy? How readable is the text
Filetypes for the documents
PDF
Image
Word doc
Google doc
raw text
html
Parameters to figure out
chunk size and overlap
embedding engine
vector storage db
scoring strategy (cosine similarity, knn, ann,)
number of chunks to return
text to return - the original chunk or something else
Security
Does anything prevent us from copying documents into S3
Is there any PII that should be considered or redacted when indexing / prior to indexing
Model selection
Will a foundation model work on its own or will it need to be fine-tuned?
Can the queries be single-turn, or will they need to be multi-turn? (i.e., some engine makes a routing decision to one of multiple models based on the classification of the query)
What latency needs? If low latency is needed, use something like Claude instant
How much volume will the system need to support?
Bedrock (serverless) or Amazon SageMaker (self-hosted) or OpenAI, etc
Monitoring and evaluation
Cost, performance, latency
Quality: figure out the "golden utterances" for people, so you can test the model as you iterate